一文深入掌握Druid 实时与历史数据处理与存储的核心引擎
Druid是一个专为实时和历史数据分析而设计的高性能、列式存储、分布式数据存储系统。它能够高效地处理大规模的事件流数据,并支持低延迟的查询,广泛应用于实时监控、广告技术、物联网(IoT)和业务智能(BI)等场景。本文将深入探讨Druid的数据处理流程、存储架构以及其核心支持服务,帮助您全面掌握这一强大的数据处理引擎。
一、Druid的核心设计哲学与优势
Druid的设计目标是解决大数据场景下的实时摄入、快速查询和高可用性问题。其主要优势包括:
- 列式存储与高效压缩:数据按列存储,便于压缩和快速聚合查询,显著减少I/O。
- 分布式架构:支持水平扩展,能够处理PB级数据。
- 实时与批量摄入:支持从Kafka等流式数据源实时摄入,也支持从HDFS等批量导入历史数据。
- 预聚合与索引:通过数据段(Segment)的预聚合和位图索引,实现亚秒级查询响应。
- 时间分区:数据按时间分区,便于数据管理和时效性查询。
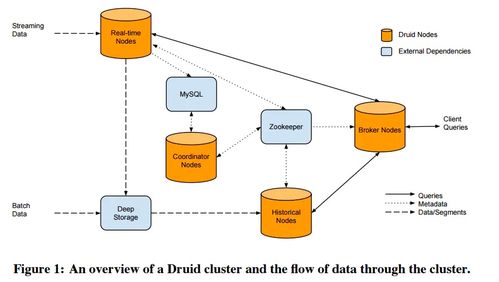
二、数据处理流程:从摄入到查询
Druid的数据处理流程主要包括三个关键阶段:
- 数据摄入(Ingestion):
- 实时摄入:通过“索引服务”(Indexing Service)从Kafka、Kinesis等流式数据源持续拉取数据,并实时创建数据段。
- 批量摄入:通过“Hadoop索引任务”或本地任务,从静态文件(如JSON、Parquet)批量导入数据。摄入过程中,Druid会对数据进行解析、转换(如维度、度量定义)和聚合(如roll-up)。
- 数据存储与段管理:
- 摄入的数据被划分为不可变的“段”(Segment),每个段包含特定时间范围的数据。段是Druid存储、复制和负载均衡的基本单元。
- 段存储在“深度存储”(Deep Storage,如HDFS、S3)中作为持久化备份,同时被加载到“历史节点”(Historical Node)的内存和本地磁盘供查询使用。
- 查询执行:
- 查询通过“Broker节点”接收,Broker根据查询的时间范围,从“协调节点”(Coordinator)获取段分布信息,并将查询路由到相应的Historical节点或实时任务节点。
- 各节点并行执行查询(如聚合、过滤),Broker合并结果返回给客户端。
三、核心存储架构与支持服务
Druid的架构由多个相互协作的专用服务组成,每个服务负责特定功能,共同支撑数据处理与存储:
- 协调节点(Coordinator):
- 管理集群上的数据段,包括监控Historical节点、将新段分配给节点、平衡负载、删除旧数据(基于保留规则)。它定期从元数据存储(如MySQL、PostgreSQL)读取段信息,并发布负载规则。
- 历史节点(Historical Node):
- 负责加载和提供数据段的查询服务。它从深度存储下载段到本地,并常驻内存以提供快速查询。Historical节点是无状态的,易于扩展。
- 代理节点(Broker Node):
- 作为查询的入口点,接收来自客户端的查询(通过REST或JDBC)。它从Coordinator获取段分布信息,将查询转发给相应的Historical或实时节点,并合并结果。Broker还缓存查询结果以提升性能。
- 索引服务(Indexing Service):
- 负责数据的摄入和段的创建。它由“Overlord”(主节点)和“MiddleManager”(工作节点)组成。Overlord分配摄入任务,MiddleManager执行任务(如从Kafka拉取数据并生成段)。生成的段被推送到深度存储,并由Coordinator协调加载到Historical节点。
- 实时节点(已演进):
- 早期版本有专门的实时节点,现在实时摄入功能已集成到索引服务中。MiddleManager可以运行实时任务,在内存中缓存实时数据,并定期将数据转换为不可变的段。
- 元数据存储与深度存储:
- 元数据存储:通常使用关系型数据库(如MySQL),存储段的元数据、配置信息和任务日志。这是集群的“大脑”信息库。
- 深度存储:使用分布式文件系统(如HDFS、S3)或对象存储,作为数据段的持久化备份。Historical节点从深度存储加载段,确保数据可靠性和可恢复性。
四、关键特性深入解析
- 数据段(Segment)的结构:每个段是一个时间分块的数据集合,包含:
- 列式存储文件:数据按列存储,包括时间戳、维度(字符串)和度量(数值)。维度列还创建了位图索引,支持快速过滤。
- 索引文件:包含元数据和位图索引,加速查询。
- Roll-up预聚合:在摄入阶段,Druid可以对数据进行聚合(如按维度组合求和、计数),减少存储空间并提升查询速度。但会丢失原始粒度数据,需在数据模型设计时权衡。
- 多租户与隔离:通过任务分配和资源隔离,Druid支持多租户使用,不同数据源或团队可以共享集群而互不影响。
- 容错与高可用:
- 服务本身设计为无单点故障,可以部署多个Coordinator和Overlord实例(通过选举产生领导者)。
- 数据段在深度存储有备份,且在Historical节点间可复制,确保节点故障时数据不丢失。
五、实践建议与最佳实践
- 数据模型设计:合理选择维度(用于分组和过滤)和度量(用于聚合),根据查询模式决定是否启用roll-up。
- 集群规划:根据数据规模、查询并发和实时性要求,合理配置各服务节点数量。例如,高查询负载需增加Broker和Historical节点。
- 监控与调优:利用Druid内置的指标(如查询延迟、段加载状态)和日志,监控集群健康。调整段大小(通常每段500MB以下)、内存配置和缓存策略以优化性能。
- 与生态集成:Druid可与Apache Superset、Grafana等可视化工具集成,也支持通过Kafka Connect、Flink等工具进行数据摄入。
Druid通过其独特的列式存储、分布式架构和专用服务组件,实现了大规模实时与历史数据的高效处理和存储。掌握其数据处理流程和核心服务——Coordinator、Historical、Broker和Indexing Service的协作机制,是构建低延迟分析应用的关键。随着实时分析需求的增长,Druid已成为现代数据栈中不可或缺的一环,值得每一位数据工程师和架构师深入学习和应用。
如若转载,请注明出处:http://www.bswoniu.com/product/40.html
更新时间:2026-02-24 09:22:59